Main menu
You are here
Tales Of A First Time Driver Developer
Since 2004, I've owned a ThinkPad A22m - a laptop that came out in 2001. Much to the dismay of certain friends, I still feel no need to purchase a newer computer. I've often said that this old hardware can do everything I need while still letting me run modern software. However, it now seems like I will have to take some responsibility for the code if I want that to still be true in the future.
 |
 |
 |
 |
 |
 |
 |
 |
Specifically, I am talking about open source ATI drivers on GNU / Linux. The four main video card lines released by ATI (now owned by AMD) have been Wonder, Mach, Rage and Radeon. I don't think Wonder cards have any features that would warrant the development of a dedicated driver but Linux drivers for the other three have been written.
The Radeon driver is actively maintained by software engineers at AMD and some people who work for other software companies. The other two? Not so much. The Rage 128 driver was especially in need of a major update recently. And since my computer has a Rage Mobility graphics card, I felt motivated to start working on the code even though I had never hacked such a low-level piece of software before. Since the effort has largely succeeded, I would like to share my experiences with editing an open source video driver. The learning curve was quite steep and when I first started reading documentation, it seemed like it was written for a different audience. This post is going to be an unadultered attempt to get a completely new reader to catch on to what I did. I'm sure I will later find out that many things written in this post are technically incorrect, but I will not edit them. I want the only knowledge communicated in this piece to be the knowledge that one might reasonably be expected to have after jumping into driver development for the first time.
First I should give a crash course on how a graphical stack on Linux is setup. You may have heard that a Linux GUI is provided by a program called the X Server. The main implementation of this used to be XFree86, now it is X.org. The X server is setup so that it can be used with any video card. In the process of setting up a GUI, some parts are inevitably card specific so X handles these parts by loading a card specific shared library. Which one it loads is either specified by the user or autodetected. This shared library is the "device dependent" part of X so it is usually called a DDX. I used the word "driver" to refer to the code trees linked above, but they should really be called DDXes.
There are a few different modes in which a video card can be used. The default is VGA compatible text mode which only gives you a text console. This is a standard that all video cards support so it doesn't require any device dependent code. A driver for this is included in the "kernel" which is the most fundamental part of an operating system. Every program that doesn't run in "kernel space" (like the X server and its DDXes) is said to run in "user space". Most users want to go beyond this and make the screen show an actual picture - a million pixels showing different colours. The simplest way to do this is to use X with the "xf86-video-vesa" DDX. VESA is another standard that is generic across all video card models. This allows programs to use the video memory - memory physically connected to the video card that is separate from the RAM on a computer motherboard. The memory allocated for storing pictures of the screen and other pictures that the video card might be expected to use is called the "framebuffer". When you see cards advertised as a "256MB card" or a "1GB card", this is referring to the size of the framebuffer. Most users want to go beyond even this experience and use the specialized features of a particular card in order to have a GUI that is faster and more responsive. This requires a specialized DDX like "xf86-video-r128" in my case.
As an aside, there is a nifty alternative to how a video card can be used on GNU / Linux. This is to display pixels that emulate the look and feel of the text console. This allows the console to have a higher resolution, update more quickly and display the occasional video. Some of these "framebuffer console drivers" as they are called use VESA, others use features of a specific card.
Anyway, using X with the right DDX allows you to accelerate 2D graphics operations. 2D acceleration is what I worked on with my inaugural contribution to the r128 driver, but I might as well say a few words about 3D. If you have a 3D shape specified by a bunch of faces, edges and vertices, figuring out what it looks like from a particular angle is expensive. It would be nice to let the GPU on the video card figure this out while the computer's CPU is free to do other things. Video card manufacturers implement two different methods for doing this - Direct3D which is only for Windows and OpenGL which is supported by most operating systems. The X server alone does not provide any support for OpenGL. That comes from a program called Mesa. Mesa provides a library called LibGL following the standards of the Khronos Group. A game, screensaver or desktop effect program can link to LibGL and say that it wants a certain 3D operation to be accelerated by the GPU. LibGL then calls device dependent code so that means there is another video card driver running alongside the DDX - one for 3D and one for 2D. To make things even more complicated the 3D driver is split into two pieces. One is a DRI driver that runs in userspace. DRI stands for Direct Rendering Infrastructure and it computes data that would have to be sent to the video card and when it would have to be sent. The other is a DRM driver that runs in kernel space and uses the kernel's Direct Rendering Manager to actually send data to the video card. The reason for having part of the code in the kernel might have to do with speed but there are also security issues related to direct memory access so it is the safest method too.
So up until a year ago, things were looking pretty good for users of old ATI cards. Kernel modules, mesa drivers and DDXes were available for mach64, r128 and radeon. But then disaster struck and the mesa drivers got removed. This is because a new version of DRI was developed years ago. Porting DRI1 drivers to use DRI2 was a lot of work, so this was only done for the most important drivers - radeon, intel and nouveau. Since maintaining DRI1 was becoming a large burden, they were dropped entirely from mesa 8.0 in a controversial move meaning that mesa no longer has support for mach64, r128 and five other GPU lines. I was quite upset when I heard this news, fearing that I would have to use old software from then on. The situation is not quite that bleak - I can still update X, the DDX and the kernel as long as I keep mesa at version 7.11.2. So this is what I did until I saw another call to arms. There are a few different frameworks within the X server for handling 2D acceleration. The oldest one is XAA and EXA is now the most common replacement for it. The r128 driver was at a particular disadvantage in this area because radeon and even mach64 already had EXA support. There are various explanations for why EXA is superior and after reading them I started to think that it might also be simple enough for me to hack. So I set out to add EXA support to the r128 DDX.
Now EXA does not stand for anything in particular but it is derived from KAA, the Kdrive Acceleration Architecture. Luckily, I was not starting from scratch because a developer named Joseph Garvin had a work in progress patch that was last updated in 2006. This taught me a lot of what I needed to know. If you are going to add EXA support to a driver, you need to have a clear idea of the memory map of your card. This refers to which memory addresses in the framebuffer are used for which types of data. It seems to me that this is a driver choice and that video hardware will work no matter how the memory map is setup.

This is the image that always comes to my mind but I don't know if these memory ranges are at all correlated with pins on the PCI bus. There were a few choices that I could make when setting this up for EXA on the r128 but the driver already supported XAA and other standard things so I wanted to make the EXA memory map as similar as possible to the memory map it was already using. Besides, Joseph Garvin had already done a lot of this work.
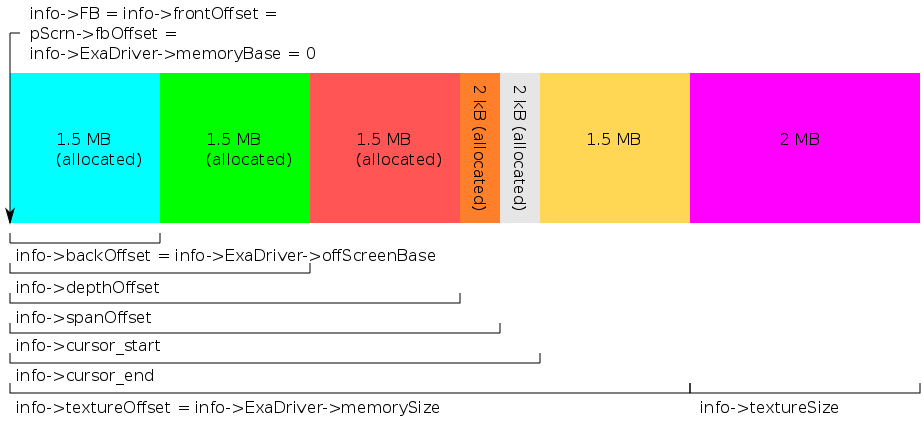
This picture is more informative and it shows variable names that you can find in the xf86-video-r128 source. First there is a front buffer. I'm calling it a 1.5 MB front buffer because the most commonly used screen resolution with this card is 1024x768 with a colour depth of 16 bits per pixel. Multiplying these out, we get 1536 kB. The front buffer is on-screen memory since it stores the pixels that describe what the screen looks like at a given moment. Everything else is offscreen memory. The back buffer is there for the double buffering technique which must be used if one wants DRI to work. It stores a sort of back up copy of the screen that is periodically copied to the front buffer. The depth buffer is also exclusively for 3D purposes. It implements Z-buffering so instead of colours, each number it stores is a z co-ordinate telling the GPU how far away a pixel should appear to be when it is part of a 3D scene. The 2 kB region after the depth buffer is called the depth span and it is only big enough for one horizontal row of pixels. It is also for some 3D application and that might be the scanline rendering technique. The next 2 kB region keeps track of where the cursor is. The second last region is used by EXA to store pixmaps and Xv data and the last region is used by DRI to store textures for 3D shapes. The 1.5 MB size of the second last region doesn't have anything to do with the 1024x768 resolution. It's just that the driver is setup to give DRI 2 MB for textures and EXA gets whatever is left. On my 8 MB card, that turns out to be 1.5 MB. If I decided to turn DRI off and not have any 3D features, the back buffer, depth buffer, depth span and texture areas would be gone giving EXA 6.5 MB. My abysmally small framebuffer also explains why I choose a 1024x768 resolution. If I chose a resolution that had twice as many pixels, the three buffers alone would occupy 9 MB instead of 4.5 MB which would be impossible for my card to store.
Now even though EXA is told that the base of its offscreen memory starts right after the front buffer, several things are allocated. This means that they are considered to already be in use and when EXA needs to store a pixmap or an Xv frame (more about these later), it will use the first piece of free memory which will be somewhere in the yellow square. It doesn't have to be this way. If you were to read the xf86-video-mach64 source code, you would see that it puts the texture region right after the depth span, then it has a memory region for pixmaps and Xv, then it allocates the cursor. It also plays a clever game with allocating and deallocating the 3D parts so that when you close all 3D windows, EXA will suddenly get more memory and when you open one, EXA will suddenly have less.
Now Garvin's patch had code for setting up this memory map and initializing EXA but the main challenge in writing an EXA driver is providing the acceleration hooks. You can find a full list of hooks in the documentation and all of them involve at least one pixmap. A pixmap is a memory object having a pointer to a bunch of pixels and a few properties. Two of the properties are width and height; these should be pretty straightforward. Another one is pitch. This is a number saying how many bytes the start of the second row is from the start of the first row. This sounds very similar to the width but sometimes there is a requirement to have rows starting at memory addresses that are multiples of 16 or some other number and extra padding introduced to enforce this causes width to differ from pitch. The last main property is the pixmap format which states how many bits are in each subpixel (if the pixmap has 24 bits per pixel, you obviously have 8 for red, 8 for green and 8 for blue but if the pixmap has 16 bits per pixel there is a choice to be made - it is often 5 for red, 6 for green and 5 for blue).
To make sure that the card knows what to do with the pixmaps, you need to send control sequences to the right registers. Unless you are serious about reverse engineering, you usually have to read some specifications to find out the memory addresses for the registers you want. The registers enumerated in the source code came from an ATI developer manual. I have not found it online because it was undoubtedly only available under a non-disclosure-agreement back in the ATI Rage days but employees of VA Linux were able to obtain a copy when they originally developed the r128 driver. Since being acquired by AMD, ATI has started putting their developer manuals online. The Rage 128 manuals are too old to be in that list so it would make sense for me to bug AMD employees to upload them. However, I didn't actually need to do that for the EXA project.
The two hooks that must be in every EXA driver are Solid and Copy. Solid is for creating boxes of a solid colour. If an application told the X server that it wanted to draw a 10x10 blue box, on its own, X would create a pixmap consisting of 100 blue pixels and send each one to the video card individually. Sending it from RAM to video RAM is known as migration. This wastes time if the GPU on the video card has its own facilities for creating boxes. A solid acceleration hook will create the pixmap in video RAM by sending only five numbers to the card - an x co-ordinate, a y co-ordinate, a width, a height and a colour - these numbers have to be sent to the right registers. Copy is for taking a pixmap that occupies one video memory location and sending it to another video memory location. A common use of it is copying offscreen pixels to the front buffer (screen). Getting the CPU to copy pixels from the first VRAM spot to regular RAM and then to the second VRAM spot would be horribly inefficient. It's better to signal a few registers on the card so that the GPU knows about the two memory locations and can perform the copy itself. Beyond Solid and Copy, the other three hooks that EXA drivers should try to implement are Composite, UploadToScreen, DownloadFromScreen. I'll get to Composite in just a moment but the upload and download hooks should remind you of migration - moving pixmaps between RAM and VRAM. How can this be accelerated beyond what is normally done? I think you have to tell the card to suspend some of its other idle tasks so that it can free up several pins on the PCI bus and perform the I/O quickly. Copy / UFS / DFS operations that copy pixmaps are collectively referred to as blits.
Garvin's patch had hooks for Solid and Copy that mostly worked. They were based on the XAA versions of the Solid and Copy hooks so most of the mysteries about how to use a certain register were already answered in that code. I updated Garvin's patch to work with the 2012 version of the r128 DDX and then noticed a slight problem with it - it prevented me from using Xv. Xvideo is an X server extension for speeding up video playback. It uses the video overlay, a system that most video cards have for quickly displaying a square image overtop of whatever else would be displayed. The r128 driver was already able to use the registers associated with my card's video overlay but it allocated the frames assuming that XAA was being used. I edited that code to conditionally allocate frames using the EXA allocator. By March 25, I had a patch that made me happy and I stuck it in a bug report hoping to get it accepted. I said that it was desperately needed and that it had at least one improvement over the initial patch that didn't get accepted. However, things were not that simple because:

I wanted to implement the Composite hook. Getting a video driver to do alpha compositing is more difficult than getting it to do Solid and Copy operations and there is no capability within XAA for this to use as a starting point. The reason I thought it would be possible was because I found r128 compositing code in an old version of the X server that used KAA. Michel Dänzer of AMD convinced me that my patch would only serve a useful purpose if I could get compositing to work. Otherwise, a user with my patch applied would hardly see any improvement over a user with no 2D acceleration. Compositing is all about transparency. A pixel on the screen has three channels - red, green and blue but a pixel in an offscreen pixmap can additionally have an "alpha channel" that stores how transparent the pixel should look. A calculation is done to convert a four channel pixel into a three channel pixel. For example, a pixel that is 100% red with 50% alpha on a white background would be converted into a pixel that is light red. This is the calculation that can be accelerated by sending it to the GPU. The fact that on-screen and offscreen pixmaps need to be in different formats for this to work immediately explains why XAA has no Composite hook. A severe limitation of XAA was that it required all pixmap formats to be the same.
Getting this to work took a lot of debugging. This was basically printf debugging but you can't see the console underneath X while X is running so you instead write lines to a log file and keep refreshing that log file. There are three ways in which a DDX can fail:
- The good way: This happens when a driver has some part that is written badly but doesn't do anything illegal. X will become unbearably slow and after you kill it, you will probably see some messages about how the event queue overflowed. You can then try to fix the bug and restart X.
- The bad way: This happens when the driver legitimately crashes by trying to write to memory that doesn't belong to it or something similar. When a typical C program crashes this way, you get a segmentation fault. A normal segfault doesn't cause a kernel panic but in an X driver it does. At first I thought that there should be a way for X to catch one of its drivers crashing and die gracefully so as to prevent a kernel panic. But then again sequestering processes like this kind of defeats the purpose of direct memory access. In short, when a driver fails this way, a reboot is necessary.
- The really bad way: A driver can also fail by doing something bad to the video card itself, like sending a number to the wrong register. When you screw up the video hardware like this, it is common to see everything freeze prompting you to restart. But a reboot alone is not enough. Corrupted bits in the video card will persist and X will be unable to start properly after the reboot. To fix this you have to leave the computer unplugged for about an hour to give the corrupted bits a chance to fade away. This happened to me three times and one of those times my backlight was also shot until a few reboots later. It was very scary.
The compositing code works by creating a 3D texture - it engages the 3D hardware for 2D purposes. So if a square picture has some transparency in it, two triangles will be created and they will be positioned at 0 depth so that they just appear as part of the screen - you don't even see the polygons. The KAA code had several lines saying "this type of compositing is not supported" and "that type of compositing is not supported" so it seemed like a lot of things weren't supported by the hardware. When I first adapted the KAA code to the current r128 DDX, I saw a lot of rendering errors which seemed to indicate to me that the hardware was trying some extra unsupported operations that those checks had missed. I systematically disabled more and more cases in the compositing hooks until my screen looked normal. I then foolishly declared that the hooks were working and tried to get the patch accepted.
What are all these combinations and cases? Well a 1984 paper by Porter and Duff describes a bunch of operations for compositing. They involve a foreground image that only partially overlaps with the background image. In some cases you only want to see the part that overlaps, in other cases you might only want to see the parts that don't overlap. The fourteen operations are: Clear, Src, Dst, Over, OverReverse, In, InReverse, Out, OutReverse, Atop, AtopReverse, Xor, Add, Saturate. When an application requests that a certain operation be done, it requests them using the render protocol. Render is another extension to the X server that can handle transparency without making the client application do all the work itself. The pixel coefficients that render uses for the fourteen above operations are mentioned in the specification. If render knows that there is an EXA driver in use with compositing hooks, it will use those instead of multiplying by the coefficients in software. I was told that a working Composite hook greatly speeds up text rendering - and it does. According to x11perf -aa10text, my card can now draw 300,000 characters per second. Before using EXA, it could only draw 50,000. Why is compositing so crucial for text when most text is not transparent? This question had me confused at first, but the answer is actually very elegant.
Text generally needs to be coloured (and even black text on a white background should be coloured if done properly thanks to subpixel rendering). To allow the widest possible range of colours, it is best to use 32 bits for each pixel so the 14x6 grid below would require 336 bytes to be sent to the card. However if we just wanted to draw a 14x6 red rectangle, this could be done as a solid picture - we could just use 4 bytes to send a single red pixel and tell it to repeat. The In operator now comes to the rescue. We can turn off certain red pixels in the block by overlaying a mask that only has transparent pixels where we want the letters to show up. Since the 14x6 mask only encodes transparency, each one of its pixels only needs an 8 bit alpha channel. So instead of sending 336 bytes, we can get away with sending 84 + 4 = 88 bytes as long as we use transparency.
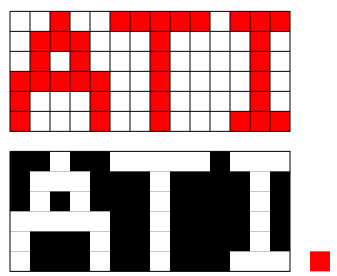
In the example above, the 1x1 red pixel is the source picture and the 14x6 mask is the mask picture. Of course it could also happen that we want the text itself to be transparent. In that case we'd need to know the background behind it (something already on the screen) and that would be the destination picture. More generally a destination pixmap is just the screen area to which the "source-mask overlay" gets copied so we need to know what it is even if it doesn't end up getting seen by the user. Sources, masks and destinations all have formats with self-explanatory names like ARGB8888 or A8 or RGB565 and some combinations of formats for certain Porter-Duff operations are unsupported by my hardware. I made the mistake of thinking that all such operations were equally likely to occur in a desktop session. I looked at my code and said "only half of the operations are disabled so the other half must be succeeding because I see a normal desktop." However, I had disabled anything involving the ARGB8888 format which is by far the most common one so my system was actually not trying to composite anything.
I started using Eric Anholt's program rendercheck which can force a certain render operation to be used. It draws a 40x40 root window in the upper left corner of the screen and uses the render extension to draw all sorts of patterns on it. This is what the squares at the beginning of this post show. It then samples the pixels and reports an error if they are different from what they are supposed to be. It's a pretty cool program but you have to watch out for a few things. Firstly, there are enough tests to make it take a really long time if you don't tell it to skip several tests. In the case of my slow system, doing all of them would take about 10 days. Secondly, you have to disable screensavers while you use it to prevent it from finding an error whenever a screensaver is running. And lastly, if one test fails, chances are more tests will fail and the size of an error log it prints out can easily be in the GB. I used this until I was satisfied that all of the tests were passing and that most of them were actually being sent to my video card.
Personally, I think Michael Larabel of the Phoronix news site has too much bloodlust for old video drivers. He always talks about killing them off and when mesa 8.0 came out - the first version lacking DRI1 support - he made a point of not even acknowledging that it's a feature some people will miss. So I chuckled when he covered a story about my patch on April 29. Users that replied to it sounded very supportive. However, I then found out yet again that my patch was not working! This caused me to get quite embarrassed because I had told the X.org developers that my patch worked and the Phoronix article was written assuming that I was telling the truth. Here is what happened. When hundreds of tests from rendercheck passed, I verified that they passed without falling back to software by reading the X.org log file. I had placed a print statement at the end of my Composite hook so the presence of hundreds of new lines in the log file told me that the Composite hook finished successfully. When I looked at the rendercheck source code, I realized that this was too big an assumption. Before rendercheck initiates the operation that will be used to evaluate your driver's compliance, it initiates a Src operation just to set things up. So when I tested Over, this initial Src operation was what successfully got sent to my driver. My driver wasn't handling it correctly but I didn't know that because rendercheck doesn't report errors based on the initial Src operation. The subsequent Over operation that really mattered appeared to pass. But it only "passed" because my driver fell back to software for the Over operation!
So I became frustrated and tried to tweak hundreds of things to try to get Over and other operations to actually work. Nothing I did seemed to have any effect so I concluded that the vertex bundles that draw the two triangles were simply not being used by the card. It took me forever to figure this part out, but thanks to some help from Michel Dänzer, I eventually got it. Rage 128 has a system designed to let you send commands to the registers more quickly. It is called the CCE for Concurrent Command Engine. It is just like Radeon's CP; Command Processor. If you don't use the CCE, commands wait in a queue and one doesn't get accepted until the card is finished dealing with the one before it. To do the actual compositing, I was using the CCE but for some initial setup commands that only have to be run once, I decided not to use it - who cares if it takes a few extra milliseconds to start the X server. These setup commands did things like engage the FPU. GPUs have a floating point unit for dealing with vertices and in fact, when you send the co-ordinates of a vertex, they have to be sent as integer representations of an IEEE float. The CCE is initialized by the kernel and when I found a convenient place in the DDX for putting the setup commands, the CCE was not yet initialized by that point. This turned out to be the problem. Some commands must be written using the CCE. When I modified the driver so that it sent the setup commands using the CCE after the CCE was initialized, I actually started to notice the vertex bundles. Then coding became a lot of fun because I got to fine tune a few aspects of the compositing. Michel Dänzer was very helpful and gave a lot of suggestions for how I could iron out the patch.
Phoronix wrote another article on July 6 and on July 17, my patch was finally accepted. Some easy patches were accepted later fixing minor issues that were noticed after the fact. I have now been given git access to the r128 driver so I will be in a better position to fix other issues and continue to modernize it. After all, this is only a small step in the journey towards having a modern DRI2 driver. Some people have said that this four month effort would have been better spent on a card that tons of people use. To this, I say that I was only able to force myself to gain this experience because no one else was working on it. Working on an actively developed driver would not have taught me as much because the projects in the Radeon driver that interest me are being pursued by graphics professionals. It is much faster for them to do the work than it is for them to wait until I figure out how to do it. If you are trying to add EXA to an old driver, you don't need to be a graphics professional to keep up. Well maybe to implement Composite without any example code you do, but for Solid and Copy, you just need a working knowledge of C, some experience searching for code snippets / adapting them for other purposes and the patience to debug for days on end. There are still plenty of drivers that need EXA support added so if you have a 3dfx, trident or s3 card for instance, I would suggest that you give it a shot. This is one aspect of driver development that actually is accessible to beginners.